





I love errors. I mean, I just absolutely love them. Mistakes are the things that reveal to me all of the things that I think I know, but actually don’t. Don’t get me wrong, I love the positive validation that comes with answering something correctly. Perfect score on my exam? Don’t mind if I do. But errors are even better. Getting something right tells me what I’ve done. Mistakes tell me what I need to do.
Submitting an R package to CRAN is a great place to pick up errors. There are a battery of tests that any package must pass before being posted to CRAN, and they’re all interesting in their own way. There’s the fairly obvious: “checking extension type … Package.” (Measure twice, cut once.) There are the slightly obscure: “checking serialization versions.” (I’m glad someone’s looking in on that.) And then there are the rather interesting: “checking for detritus in the temp directory.” (“Detritus,” you say?) This is all very good and reasonable stuff, and it’s a big reason why the R ecosystem has flourished. Users know that all CRAN packages have passed a set of basic checks to ensure that they will work, as advertised on multiple platforms. For me, though, I just love fixing all the tests that I don’t pass the first time around.
Just as much as errors, I also love being lazy. If you ask me whether it’s raining, I don’t even want to look out the window; I’ll just call the dog in and see if it’s wet. (I wish I could take credit for that folksy saying. I first heard it on a Redd Foxx record.) I’ve spent countless hours and a lot of late nights figuring out new ways to wallow in my own indolence. It’s fair to say that I won’t rest until I can do nothing but rest. So you can imagine how happy I was when I figured out how to learn about my own mistakes and be lazy at the same time!
It turns out there’s a way to have the CRAN check run automatically whenever your repo (repository) gets pushed to a git-based cloud platform like GitHub, BitBucket or GitLab. This is possible through the magic of “continuous integration.” What does continuous integration mean? Simply put, it’s a way to automate software construction whenever one component changes. This could be anything from running a set of tests, building a website or pushing a model to production.
In this article, I’ll focus on the testing. Software is complex. Even straightforward systems involve many different elements, any one of which could be changing at any given time. At enterprise scale, where components are designed and built by multi-person teams and need to be integrated, this gets really complicated really fast. Changes made to one component need to be individually tested, but we also need to ensure that the whole system can accommodate the changes. Enter continuous integration (CI), which automatically runs those tests whenever any changes are detected in any component.
There are a number of options in the marketplace that vary in terms of open versus closed license and pricing. Travis and AppVeyor are two of the more popular options, but Wikipedia lists about a dozen others. Travis is the first one I started to use and the one I’ll discuss here.
Years ago, I built the R package raw (R Actuarial Workshops) to ease the hassle of providing data and a basic setup for attendees of the CAS R workshops. Though the package is pretty basic, even something as simple as raw has been built and rebuilt many times. Figure 1 shows a history of package builds. All of the builds were done by Travis in response to a push of the repo up to GitHub. Note how easily my laziness gets accommodated. I was going to push to GitHub anyway, but Travis is now doing work for me!

In the listing, we can see which code changes lead to errors and which lead to results that may pass a submission to CRAN. Green passes; red doesn’t. Travis will even send me an e-mail letting me know what happened. Each entry corresponds to a specific git commit. This means that I can easily look at the source code and understand where things went wrong. Another great feature of the Travis CI setup is that it will test on multiple R installations. CRAN requires package developers to test on the development version of R. Keeping up with the leading edge of R is a slight headache even for an R enthusiast like me. Using a CI tool outsources that.
Things get even better. The basic test for R in Travis is to run the battery of CRAN checks that I alluded to above. But CRAN checks are only as good as the unit tests contained in your package. If you don’t write any tests using a framework like testthat, you’ll have no idea whether your code will even work. Ideally, we’d like to execute every line of code in our package and ensure that we’re getting the results we expect. However, when I write unit tests, there’s no guarantee that the tests will traverse every path of execution in the code I’ve written. For this, we need to look at “code coverage.”
Code coverage shows how much of your source actually gets called during unit testing. For this, I use a service called Codecov but there are others out there. Whenever Travis finishes building my R package and running CRAN checks, it sends a report over to Codecov. Figure 2 shows the results from imaginator, a claim simulation package that I wrote. We see a list of source files and the portion of executable lines which get tested. Note that one file “ClaimsByLinkRatio.R”, is fully tested, whereas one, “IDs.R” doesn’t get tested at all. The others are somewhere in between.

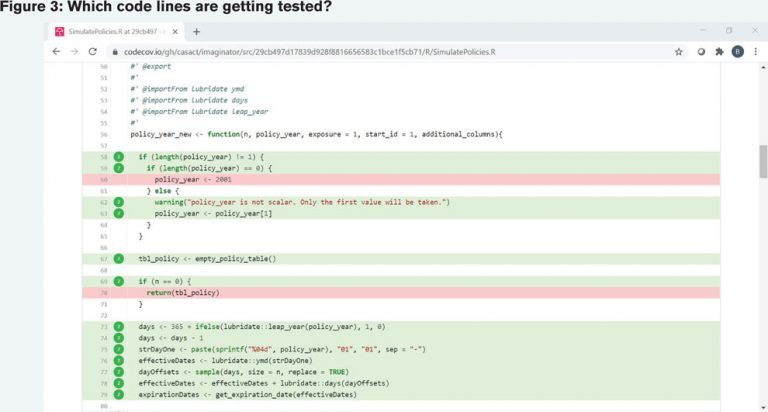
I can zoom in on those source files to see where I need to make changes. Take a look at Figure 3. The green lines execute during a test and red ones don’t. Non-executable content like comments is ignored. In this specific instance, I’m checking to see whether a user has passed in a zero-length vector. If that happens, I’d like to give some feedback to the user or rely on a sensible default or both. However, the red shading on line 60 shows me that I don’t have any tests that consider that.

This is fantastic news! It means that I have made a mistake, but I have a very lazy way to find it. I can now write a new unit test that attempts to trigger execution of line 60. After I commit that change and push it to the cloud, do I need to do anything? I do not. Travis and Codecov do all of that for me.
So what does all this mean?
- Learn to love mistakes. They’re incredibly valuable and shouldn’t be wasted.
- If you start using git in the cloud, you can plug into a wide array of tools that will:
- Increase operational efficiency (“efficiency” == “laziness”).
- Enhance transparency (“What checks did we run before we released this to production?”).
- Reduce enterprise risk (“What tests did we leave out?”).
As always, I’d love to hear what experiences others have with this element of their workflow. Until then, I’m going to go take a nap.


