









For P&C professionals, the concern with large language models (LLMs) is not whether they can chat but whether they can be relied on for actuarial computations. At the recent Casualty Actuarial Society 2025 Annual Meeting, Xuan You, senior actuarial data scientist for Ledger Investing, explored how specialized computational tools can transform LLMs beyond simple interactions and into powerful assistants for complex actuarial analysis.
Architectural constraints
LLM use cases present an interesting dichotomy. While capable of complex problem-solving such as assisting with medical diagnoses and winning math competitions, LLMs can simultaneously fail at basic tasks like counting and comparing numbers. Xuan You explained that these challenges arise from the basic limits in how models are built and trained.
At their core, LLMs are sophisticated statistical models whose function is to predict the next set of tokens (or chunks of words) in a sequence based on vast amounts of data. Their intelligence emerges from a three-phase learning process:
- Pre-training: Models train on a colossal amount of text data to learn raw patterns of language, grammar, writing styles, and facts about the world, developing reasoning to predict subsequent words.
- Fine-tuning: Models train on user-specific datasets, instructions, and responses to assist a user by responding to prompts.
- Reinforcement learning from human feedback (RLHF): Model behavior is refined to align with user preferences.
However, this predictive modeling approach suffers from two primary weaknesses that introduce undesirable results:
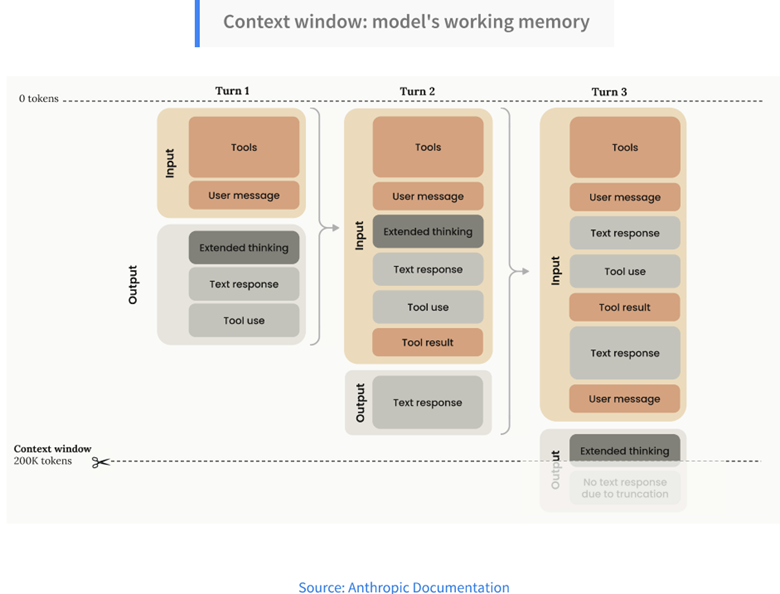
- Finite Context Window: Models have a fixed size working memory, or context window. This window holds the system message, the user’s current question, any attached files, and the entire conversation history. Because the total token count compounds with every turn, the window can fill up quickly. Once this limit is reached, models must begin dropping earlier parts of the conversation, leading to users repeating information. This introduces unacceptable risk in chained tasks like loss development or cohort analysis, where historical traceability is paramount.
- Token-Based Calculation: Models struggle with tasks requiring mathematical precision such as counting letters because they operate on tokens rather than individual numbers or letters. When asked to calculate, models will predict the most probable word or words based on patterns it has seen, not discrete logic needed for computation. Relying on these predictions for critical numerical analysis effectively equates to the model taking a wild guess.
Supplemental tools
Reasoning models are trained to generate a long internal chain of thought (hidden “thinking tokens”) before providing a final output. While allowing models more time to track and validate their internal logic, this step-by-step process can fall apart for tasks requiring precision. Enhancing reliability, Xuan You explained, will require bridging the model’s powerful capacity for pattern recognition with deterministic external tools.
In practice, LLMs can assess user intent while calling upon designated tools like calculators or subroutines to perform calculations based on reliable external codes. Codes are fed back to the LLM for final interpretation and response, thus eliminating model limitations and ensuring that critical calculations are deterministic, traceable, and potentially reproducible with immaterial differences. Such operations can improve actuarial workflows such as fitting distributions or forecasting future events.
Through these tool integrations, LLMs become “agents” that can reason iteratively, call external functions, and reflect on results until a goal is met. The agent’s path adapts dynamically based on previous tool use outcomes. Xuan You demonstrated two key use cases:
- Data extraction: Paired with the right tools, models can sift through “fuzzy” (unstructured or inconsistent) data using their strengths in pattern matching and understanding of semantic similarities to extract information like evaluation date, regardless of format, location, or typos. This approach uses natural language context rather than hard-coded if/else logic statements, reducing the maintenance burden of updating code for every possible case encountered.
- Iterative reasoning: Agentic loops are critical for managing unexpected outcomes from unexpected input. For example, if the agent is tasked with finding an incurred loss for a claim but the field is missing (null), it can try to derive the answer from component data such as paid loss plus case reserve. If that fails, the agent can pivot and attempt to query the full transactional database to complete the task. This adaptive reasoning leads to a higher rate of success. For more exploratory queries, a tool can add real-time input by a human in the loop to review and approve the code before execution.
 With LLMs developing at a rapid pace, Xuan You advised professionals to focus on optimizing systems based on their expertise rather than creating complex custom software to perform tasks that AI developers may soon embed within their core models. Key strategies include:
With LLMs developing at a rapid pace, Xuan You advised professionals to focus on optimizing systems based on their expertise rather than creating complex custom software to perform tasks that AI developers may soon embed within their core models. Key strategies include:
- Validation and testing: Document known successes and failures to build a test set for validating improvements when models are switched.
- Deliberate context management: Actively manage the context window to reduce the impact of limited memory, such as instructing the model to compress and summarize prior steps or splitting large tasks by running smaller, parallel sub-agents.
- Feedback loops: Log the final output as input to allow the LLM to inspect its own work and identify improvement for future iterations.
- Business rules, test sets, and benchmarks: Apply expertise to clearly document business rules, create generalized test sets, and establish outcome benchmarks, facilitating quicker model-to-model knowledge transfer and more effective iterations with future models.
- Workflow orchestration: Explicitly document the logic behind how different parts of the system connect, not simply how the model handles each individual component.
Augmentation, not replacement
LLMs are dramatically transforming process efficiency, allowing professionals to maximize quality outputs while using fewer resources. Xuan You emphasized that this shift augments, rather than replaces, professionals’ capacity for higher-value strategic analysis.
The technology remains an advanced tool, but it is the insurance professional’s subject-matter expertise and judgment that truly makes the solution valuable. LLMs have no intentionality and do not know specific context, the company goals, or the human interworking of the regulatory environment. For insurance professionals, engaging with this technology is essential. Just like developing actuarial judgement, mastering AI requires hands-on experience.
William Nibbelin is a senior research actuary for the Insurance Information Institute.


